You have two filesystem trees, A and B. You want the files on both sides to be the same.
Cases that you need to handle:
Right about this point in time, you’re in trouble. (That was fast!) Only one of those situations can be handled automatically, and that’s if the file is identical on both sides. You need a lot of user input to figure out what the directories should look like, and users tend to say “too hard!” Unison assumes that if a file is present on one side and not on the other, it has just been created. So it copies it across. Already we’re in dangerous territory because this is frequently not what you want to do.
If the file exists and is different, you have to ask the user how to merge them or which one to pick. Asking regular users how to merge files is a bad idea. (Asking developers how to merge files is usually a bad idea.)
Sigh.
This algorithm is not going to work very well. It doesn’t handle any common cases, makes a lot of mistakes in its assumptions, and asks users too much information (which will probably be wrong anyway). Anyone using this algorithm in their synchronization product (*cough* Microsoft *cough*) is going to have a lousy product.
(Don’t get me wrong. I like Office. I like many Microsoft games. I’m not anti-Microsoft at all. It’s just Sturgeon’s Law: 90% of everything is crap.)
Unfortunately, this case is unavoidable on the very first synchronization of a pair of trees. We have no history data -- even disconnected history data -- and so cannot make informed decisions about what’s new, deleted or changed. The files just are or they are not and we can’t say which of the two trees is correct.
The next refinement is to store history data when you look at the file trees. Every time you perform a synchronization you record some metadata for each file. You want to store the filename and the modification time. That way, when you do the next synchronization, you look at what changed between time X and time Y and apply those changes to the remote file tree, somewhat like generating a diff and then patching a tree. You do this twice -- once for each direction (A to B and B to A). You can get conflicts, of course.
Conceptually, this looks like:
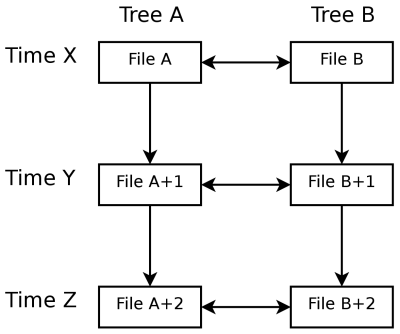
Compare this with the first algorithm, which looks like this:
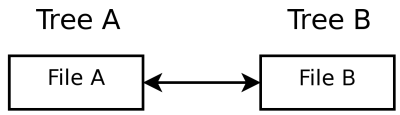
Note that if you have no history data, Algorithm 2 works exactly like Algorithm 1. Badly.
This all operates much like a version control system and has similar problems and implications. A VCS usually can’t detect renames of files or directories -- you have to explicitly tell the VCS what you’ve done. When you want to perform a synchronization you have to traverse the entire directory tree to find out what’s changed -- and this can be very time-consuming. The metadata has to be stored somewhere. Merges almost always require manual intervention and will often be unresolvable (either the user won’t know what to do and will just overwrite one side, or the file format won’t support lines-of-text style merging).
Also note the similar distinction between traditional client-server VCS (e.g. CVS, Perforce) and modern distributed VCS (Mercurial, git). Client-server VCS and propagates the nodes (or the actual files being worked on). Distributed VCS propagates the edges (or diffs). Algorithm 1 is looking purely at the file data and attempting to match it on both sides; algorithm 2 is looking at the changes between the ’sync points’ (or nodes) and propagating the changes.
The actions table for each file looks something like:
| File A change | File B change | Action |
|---|---|---|
| Created (checksum P) | Created (checksum P) | Nothing |
| Created (checksum P) | Created (checksum Q) | Merge |
| Deleted | No change | Delete |
| Deleted | Deleted | Nothing |
| No change | No change | Nothing |
| Modified | No change | Use file A |
| Modified | Modified | Merge |
(The actions for File A and File B can be interchanged -- I didn’t feel like writing out those cases twice.)
If you include the possibility of renames (and horror of horrors, renames with modifies) then you can get a whole lot more combinations and it gets really nasty. I must give kudos to SourceGear for Vault for this: it does handle all of those nasty cases, a headache which I can do without.
Detecting what’s happened between time X and time Y is similarly mechanical. For a given file:
| Time X | Time Y | Change |
|---|---|---|
| Does not exist | Exists | Created |
| Exists | Does not exist | Deleted |
| Checksum P | Checksum P | Nothing |
| Checksum P | Checksum Q | Modified |
Without having looked at the source code, I’d say this is the algorithm that Unison uses. I’d also guess that most ‘proper’ synchronization programs use this. It’s the simplest thing that works in most cases.
Note that you also need to be able to reliably detect a change in a file. The (almost) infallible way to do this is to hash the file. I say almost because hash collisions do happen -- they’re just extremely rare. ‘Extremely rare’ becomes a lot more common when you’re talking about a million files (32 bits of hash is not enough).
The other option is to look at the modification time of the file. Software can and does manipulate the modtime, however, and you might miss changes. Users might change the system time and confuse your sync program (if a change was made a long time ago). You might not be syncing to a device that has a real-time clock (some mobile phones, notably). You also have to sync the times between the two systems, but that’s not too hard.
Aaaanyway, the gist of it is:
Some filesystems such as JFFS2 keep a revision number on each block (roughly). If the revision number goes up, you can be assured that a write has happened regardless of what the modification time says. This is not a common feature, however, and probably not accessible to userspace programs anyway. There’s no easy solution here.
Algorithm 2 (a.k.a. ‘what everyone is using’) has some shortcomings:
There are also some usability issues:
Here’s how I’ll fix these problems.
The existing tools require you to manually initiate a sync, at which point you’ll have a few minutes of disk grinding. I’d rather have the program running constantly and being notified of changes as they happen. The common case is that only a few files will change between syncs -- reading all of the files is inefficient.
What I want is an API that notifies me when files change (or are created or deleted). I think inotify will do this, perhaps FAM. I have no idea what to use on Windows or OSX yet. On a technical level, this is an unsolved problem.
There is a risk here that if files are modified while the application is not running (and hence not receiving notifications) the modifications could be lost.
The fallback option is to scan the file trees while the machine is idle. If you’re checksumming files to detect changes, this can happen during idle time as well.
I think idle time is a grossly underutilized resource right now -- we could be doing virus scanning, file indexing, backups and the like constantly instead of at intervals (3am cronjob) or while the user is trying to use the system (like most on-demand virus scanners).
If you’re going to scan all of the time, you might as well copy files straight away rather than waiting until the user requests a sync. This will cut down the odds of a merge conflict somewhat, since the files are less likely to be modified simultaneously on both sides. This introduces the idea of a pair of machines being connected; while they are connected, their files are always synchronized. Since you’re probably modifying small amounts of data at a time, this will work reasonably well over a slow network connection.
Another way to prevent merge conflicts is to lock a file on machine A if it’s being written to on machine B. This prevents an application on machine A from modifying it at the same time.
A common situation is to have a laptop and a desktop that you want synchronized together. You have the laptop at home and sync the files. You take the laptop to work, but because you’re on a different IP the sync program thinks it’s a different machine. If you give each machine a UUID or name, you can be (reasonably) sure of its identity and hence use the right indexes or file trees.
If you’ve got a checksum of each file (or just the modification time and size) and you detect a file deletion, you can look through any new files and see if they’re actually the same file. You can then infer that a file was moved or renamed rather than deleted and a new file created, saving time and bandwidth during the synchronization. It may be possible to optimize this further by looking at inode numbers or their equivalent on whatever filesystem is in use.
In my classic inability to actually focus on a single task for any length of time, I’ve been working on SyncDroid.
I’ve been attacking the tricky areas of data storage and what I refer to as the ‘datapath’ -- the chain of events that takes place between a change occuring on a computer and it propagating (across physical space and time) to another computer . I can partly explain why nobody has done this before: it’s really tricky.
Unison (and most other synchronizers) make some simplifying assumptions:
Unfortunately, none of these are true for SyncDroid. They have interesting consequences.
This makes configuration management really easy: you always look to the master computer. In network-connect hosts, the master is (by definition) contactable, so you can just tell it to update its configuration with any changes made on the slave end.
SyncDroid doesn’t have this luxury. In the case of USB-drive synchronization, the two computers cannot just tell each other about changes. So there’s an interesting sub-synchronization problem: in order to know what data we need to synchronize, we need to synchronize the configuration first.
There’s really only one trap if you use this assumption: files might change between the time you detect a change and when you actually synchronize it. This is easy to solve if you take out an exclusive lock on the file-being-synchronized and ensure that it still looks like it did when you scanned it.
SyncDroid cares about lots of points in time. Because it syncs constantly, we have to be very careful about what state we think a file is in versus what state it actually is in. If you’re doing syncs to multiple partners, you have to keep track of all relevant metadata for all partners. If a partner goes away -- say the user loses the USB drive -- we shouldn’t waste time and resources tracking data that will never be used. And we can’t just rescan things constantly or lock files because that would hurt performance (or make it impossible for users to actually do work). I’m a user of this thing, too, and if it doesn’t perform acceptably, I won’t use it!
On a network-connected synchronizer, this is easy. You run some variation of the NTP protocol between the two hosts and calculate an offset so that you don’t disturb the user’s clock. You can then work out relative change timings and the best course of action.
Because this version of SyncDroid works over USB drives, it can’t synchronize times easily. I get around that with a ‘mountcount’ -- it’s just a number that is incremented every time the metadata on a drive is loaded. RAID arrays use the same idea to detect drives that were unplugged from an array and are now out-of-sync with the rest of the array. Each computer using a USB drive can then use the mountcount to determine relative change times without being dependent on the computer’s clock, which will probably be wrong.
The consequence of the mountcount is that multiple access to the metadata is strictly forbidden. This is reasonably easy to ensure and shouldn’t be visible to the user.
This is a big one, and it’s one of the major reasons I started this project. None of the current synchronizers are sensitive to the user. Perhaps I’m a dreamer, but I would like my files to be synchronized without taking a massive hit in PC performance (or battery life).
Unison (as well as most synchronizers) will do exactly what you tell them to. If you say ’scan for changes’, they will scan right now. If you say propagate changes, they will propagate right now. While they are working, the computer is struggling under massive IO load, and if you have large amounts of data (like I do) that could lead to several minutes where the disk is spinning and you can’t use the computer and you have to sync right now because your plane is leaving but it’s still running and argh I’m going to be late.
SyncDroid has a fairly involved set of priorities to determine under what circumstances it should scan and sync and bookkeep. For example, it has two scanner types: a notification scanner (which uses the OS to determine when files have changed) and a comprehensive scanner (in case SyncDroid wasn’t running and you changed a file). The notification scanner runs all of the time, but if you’re on battery or using the computer, it just remembers the changes in RAM and gets out of the way as quickly as possible. The comprehensive scanner only runs when the computer is connected to power and you’re not using it. In this way, you get the effect of non-stop change scanning without any perceptible difference to your computer’s responsiveness.
There is a big ‘but’ here, and it’s one of those annoying engineering tradeoffs: if you are not aggressive enough about scanning, you will miss changes (say, the user disconnects their laptop without warning). If you are too aggressive, you’ll slow down the computer. The trick is to find a set of tradeoffs that works well in most circumstances. In those cases that it doesn’t work, you can warn the user and give them an opportunity to fix the problem (by plugging the laptop back into the network for a minute, for example).
And then, there’s the hairy issue of where to put all of this data that we’re collecting. What we have is roughly a parallel filesystem to the one on the disk: for a file, we want to store some metadata. The best way to store this, from a design point of view, would be to store it in the filesystem itself, but this is impractical for a number of reasons (don’t want to change the user-visible view of their data, no filesystem support, differing semantics between systems, and so on).
So we have to create a filesystem within a filesystem. It’s another meta-problem like the sub-synchronization problem in configuration management. I considered doing this in the literal fashion -- creating an image on disk with a virtual ext2 filesystem. Instead of files, there would be structs of metadata that I had collected. Licensing issues were, well, issues here, and it would require me to maintain a fairly complicated data access layer. The big technical problem is that contemporary filesystem assume a constant-sized disk, while I wanted to be able to expand and shrink the image size dynamically.
My stopgap solution (while this is all stubbed out in my code) is to use a YAML file. I adore YAML. It is not a high-performance data access layer, however, and it was not designed as such. It’s just very easy to use.
Another option was a custom C data type -- or, phrased another way, ‘write my own filesystem’. Lots of effort. Transaction management is a big hairy problem that I don’t want to get into.
Finally, SQLite. I love SQLite -- it’s very easy to use and gives you very powerful query functionality. It handles on-disk consistency well and -- used sensibly -- can be very high-performance.
Many applications, sadly, do not use SQLite in a sensible fashion. (I’m looking at you, Meta-Tracker). Like any SQL database, you can do silly things to it that will absolutely destroy its performance characteristics. A classic in this situation is if you want a directory listing and your rows look like { filename | data }; the database needs to do a ’starts-with’ check on each row in the database because there’s no easy way to index efficiently by filename and retain simplistic tree-searching operations. This is Really Really Slow.
My current plan is to solve this by implementing a more traditional inode/parent structure within my database schema. I have the big advantage of knowing exactly which operations are necessary (read record by path+name, write record by id, create record by path+name, list children by path) and so can optimise specifically for them.
