To test performance across varying dataset sizes, we sample from a two-component inverse Gaussian mixture model with known parameters. Only a single dataset is fit.
| Dataset size | CPU time (seconds) | GPU time (seconds) | GPU speedup |
|---|---|---|---|
| 100 | 0.00620 | 0.01576 | 0.39 |
| 1,000 | 0.06032 | 0.01572 | 3.84 |
| 10,000 | 0.67876 | 0.03924 | 17.30 |
| 100,000 | 6.35048 | 0.19740 | 32.17 |
| 1,000,000 | 67.98868 | 1.87952 | 36.17 |
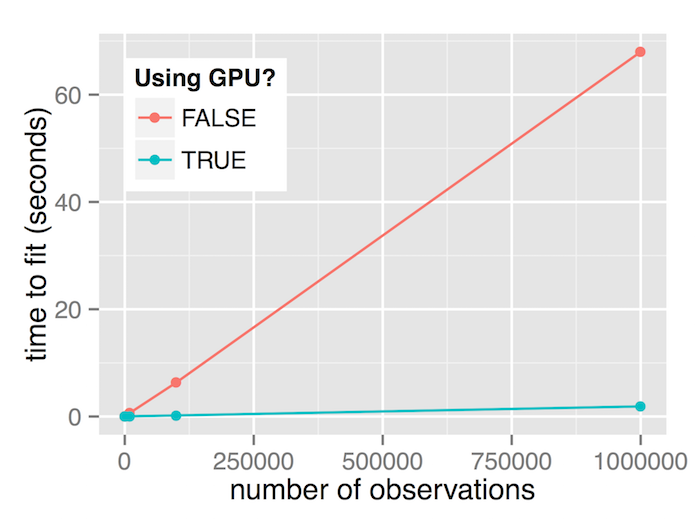
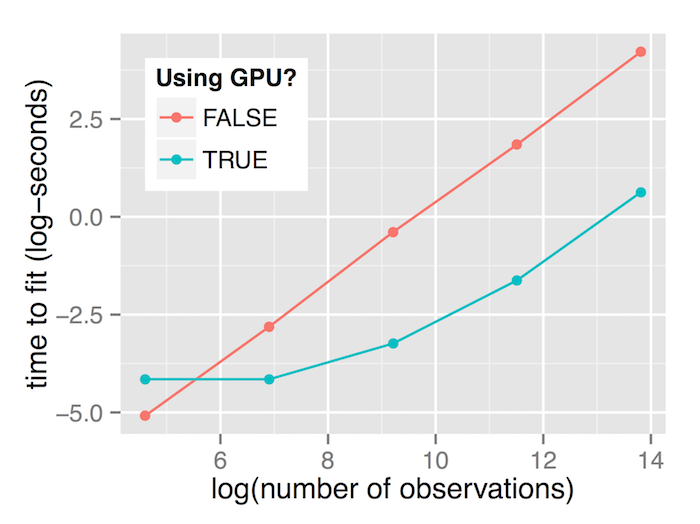
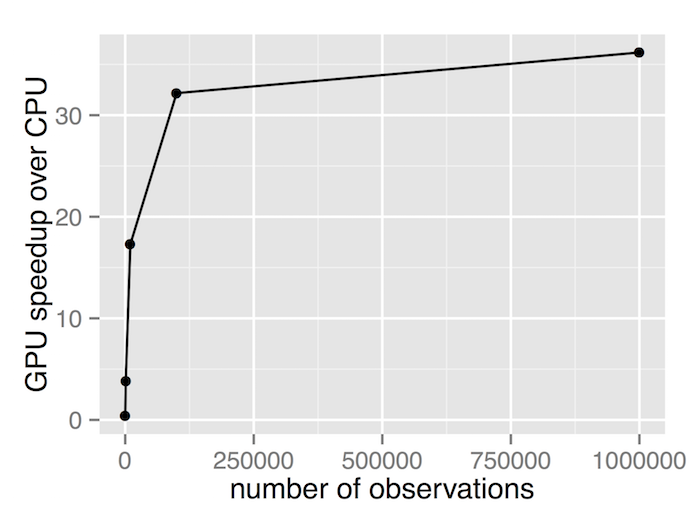
On the test hardware, we see that the GPU is slower for small dataset sizes (100 samples) but outperforms the CPU for larger dataset sizes. For datasets with 1 million samples, the GPU runs around 36 times faster than the CPU.
In this case, the dataset size is held constant (2000 samples) and we fit many datasets simultaneously, generating them in the same way as for the single dataset case.
| Number of datasets | CPU time (seconds) | GPU time (seconds) | GPU speedup |
|---|---|---|---|
| 1 | 0.10452 | 0.02092 | 5.00 |
| 10 | 1.12048 | 0.05364 | 20.89 |
| 100 | 10.12788 | 0.35904 | 28.21 |
| 1000 | 102.40840 | 3.42036 | 29.94 |
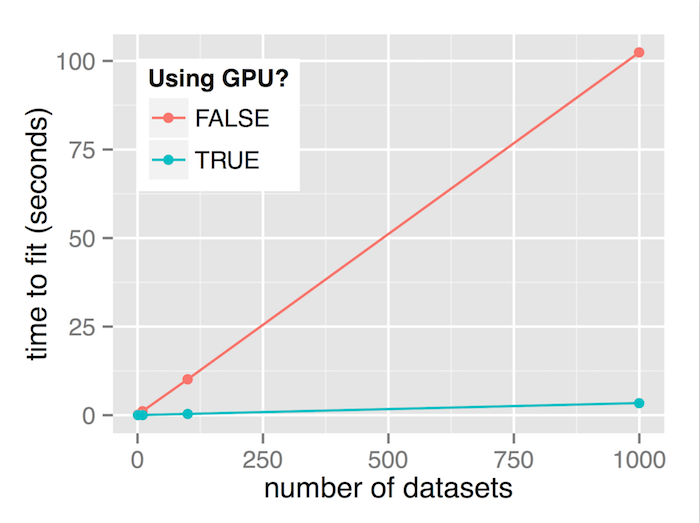
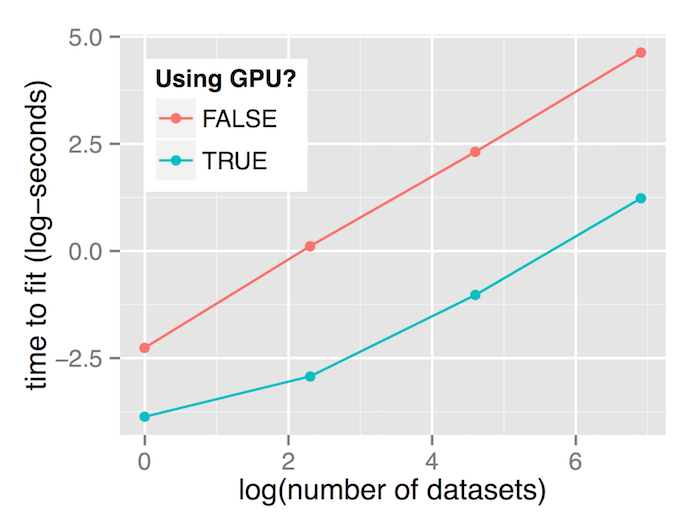
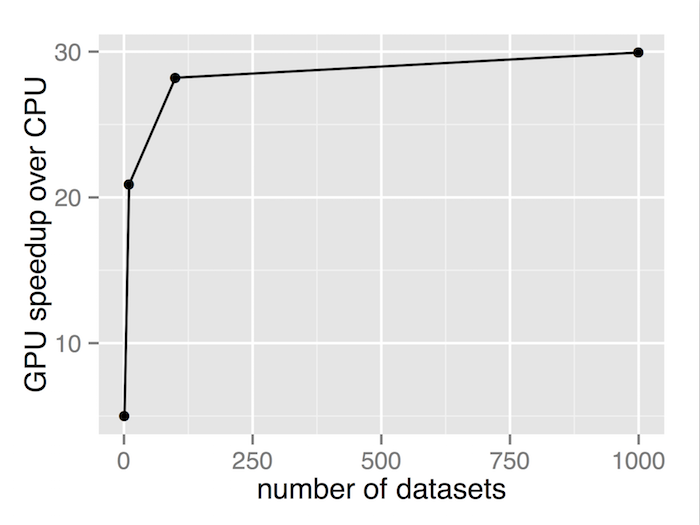
We see similar results – the ratio of GPU-CPU performance increases as the number of datasets increases. When 1000 datasets of 2000 samples are being fit simultaneously, the GPU runs around 30 times as fast as the CPU.
Comparing performance of CPUs vs. GPUs is somewhat unsound; there is no obvious way to say “this CPU is equivalent to this GPU”. Most papers, including this one, compare performance using whatever hardware the author had available at the time (Gillespie, 2011). No effort was made to optimise the CPU implementation, while significant time was spent optimising the GPU implementation, an issue discussed in depth in (Lee et al., 2010).
Fortunately, services such as Amazon EC2 (Services, ??) provide an alternative way to compare the CPU and GPU approaches: cost of rental. For a given price, one will be able to rent a certain amount of hardware which will perform the desired computations in an amount of time. Both CPU and GPU time can be rented. A fairer way to compare the two technologies is the cost to perform your computation.
A summary of the machine configurations is available at Services (2015). For reference, ECUs are a measure of allocated CPU capacity. The US East region was selected as it is generally the lowest priced.
For the CPU implementation, we selected a c4.large instance as they provide the best price-performance ratio at the time of writing (eight ECUs and two CPU cores at USD$0.116/hour as of 2015-06-09). t2 instances are not suitable as they provide ‘burstable’ CPU performance; they are not intended for long-running jobs. This machine has two CPU cores, but the R implementation will only use one. As there are no dependencies between datasets, we will assume that additional CPU cores will provide a linear speedup (that is, with appropriate software, we could obtain double the performance with double the CPU cores). The rationale for this is explored further in the linear speedup assumption. Also note that pricing for c4 instances is close to constant per CPU core and ECU allocation; the cost-to-fit ought to remain constant regardless of instance choice.
| Name | Number of CPU cores | ECU allocation | Price per hour (USD) |
|---|---|---|---|
| c4.large | 2 | 8 | 0.116 |
| c4.xlarge | 4 | 16 | 0.232 |
| c4.2xlarge | 8 | 31 | 0.464 |
| c4.4xlarge | 16 | 62 | 0.928 |
| c4.8xlarge | 36 | 132 | 1.856 |
For the GPU implementation, we chose a g2.x2large instance at USD$0.650/hour. Rephrasing this in terms of speedup ratios, the GPU implementation must achieve a 0.65/(0.116⁄2)=11.2x speedup ratio in order to break even on cost.
As before, all datasets contain 2000 randomly generated samples.
| Datasets (D) | CPU time | GPU time | CPU cost | GPU cost |
|---|---|---|---|---|
| (seconds) | (seconds) | (USDx10-6) | (USDx10-6) | |
| 1 | 0.08912 | 0.01708 | 1.44 | 3.08 |
| 10 | 0.87360 | 0.06940 | 14.07 | 12.53 |
| 100 | 9.17784 | 0.63868 | 147.86 | 115.32 |
| 1000 | 84.44992 | 6.39072 | 1360.58 | 1153.88 |
From this, we can see that the GPU implementation is slightly more cost-effective than the CPU implementation for larger problems. The difference is not large and could probably be eliminated altogether with some optimisation work on the CPU implementation.
These prices differences may seem to be trivial (who cares about microcents?) but recall that use cases may include many more datasets (tens of thousands of datasets is the intended use case) and require random initialisation to achieve a good fit (100 random initialisations means 100 times as much work, and therefore cost). For 40,000 datasets and 100 random initialisations, the cost is around USD$5.44 using the CPU implementation and USD$4.62 using the GPU implementation.
For the large dataset test, we obtain the following results:
| Samples (N) | CPU time | GPU time | CPU cost | GPU cost |
|---|---|---|---|---|
| (seconds) | (seconds) | (USDx10-6) | (USDx10-6) | |
| 100 | 0.00724 | 0.01616 | 0.12 | 2.92 |
| 1,000 | 0.05264 | 0.02032 | 0.85 | 3.67 |
| 10,000 | 0.57628 | 0.03264 | 9.28 | 5.89 |
| 100,000 | 6.03700 | 0.22568 | 97.26 | 40.75 |
| 1,000,000 | 50.11764 | 2.25400 | 807.45 | 406.97 |
For sufficiently large problems, the GPU instances can perform the model fits at roughly half the price.
Amazon Web Services. Amazon EC2. URL http://aws.amazon.com/ec2/.
Amazon Web Services. Amazon EC2 pricing, 2015. URL http://aws.amazon.com/ec2/pricing/.
C Gillespie. Reviewing a paper that uses GPUs, July 2011. URL https://csgillespie.wordpress.com/2011/07/12/how-to-review-a-gpu-statistics-paper/.
VW Lee, C Kim, J Chhugani, M Deisher, D Kim, AD Nguyen, N Satish, M Smelyanskiy, S Chennupaty, P Hammarlund, R Singhal, and P Dubey. Debunking the 100x GPU vs. CPU myth: an evaluation of throughput computing on CPU and GPU. In ISCA ’10 Proceedings of the 37th Annual International Symposium on Computer Architecture, pages 451–460. ACM, 2010.
